2004-12-03 Fri
■ 秀丸用RCS チェックアウト
バージョンの履歴がとれるようになったところで、過去の特定のバージョンを取り出してみよう。
cop.mac というマクロを使う。配布されたままの状態では動かないので[2004-12-02]にあるように修正しておこう。"filename2" を "basename" に書き換える。怪しいダブル・クオートのあたりも、ちょっと直す。
修正後のcop.mac
$r1 = input("リビジョンを指定してください");
$rev = "-r"+ $r1;
run "co -p "+$rev+" " + basename + " >con";
次のファイルは v 1.3 であるが、前のバージョンを参照したいとする。
$Id: remoteclog.txt,v 1.2 2004/12/06 08:58:45 zuihu Exp $ RCSのテスト テスト続行 おっとしくじった。
2つ前のv1.1 に戻りたいとしよう。cop.macを起動して、1.1と入力する。これだけでOK。
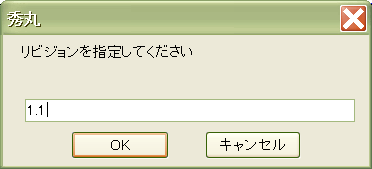
RCS/citest.txt,v --> standard output revision 1.1 $Id: remoteclog.txt,v 1.2 2004/12/06 08:58:45 zuihu Exp $ RCSのテスト
RCSがテキスト・ファイルの保存方法として、いかに強力なものであるかがお分かりだろう。
本来のRCSのお作法は、coコマンドで作業ファイルを取り出して、これを編集し、区切りがついたらciコマンドで新バージョンを登録、作業ファイルは消去という流れをとる。なかなか厳格な武士のお作法である。
この方法は、たしかに「あちこちのフォルダに同じファイルがあって、どれが本物かわからなくなる」という事態を防ぐことができるし、共同作業にも向いている。
しかし、サンデー・プログラマやウィークエンド・文豪がテキストを管理するのには、あまりに煩瑣でめんどくさい。ここでご紹介した方法は、バックアップとしてRCSを利用する方法である。RCSのお作法に従う必要がないし、ciコマンドやcoコマンドを理解する必要もない。お気楽でよろしいのではないかと思う。
筆者もこれでやっとRCSが使えるようになったのであった。
(2004-12-03 04:43:56)
■ 秀丸用RCS
秀丸用RCSマクロ[2004-12-02]の修正方法を書いたが、肝心のRCSシステムの入手が意外に困難かもしれない。RCSマクロに同梱されているREADMEのアドレスが切れてしまっているのだ。cygwin もデフォルトではRCSがインストールされない。
一番簡単なのは、RCS本家からのダウンロードである。
http://www.cs.purdue.edu/homes/trinkle/RCS/rcs57pc1.zip
解凍して、\bin\win32 以下にある一連の exe ファイルを C:\WINDOWS\system32 にコピーすればよい。
RCSのうれしみを実感するには、保存するファイルの先頭に $Id: remoteclog.txt,v 1.2 2004/12/06 08:58:45 zuihu Exp $ という記号を書いておこう。ci.mac を実行するたびに、この行にリビジョンが記録される。
$Id: remoteclog.txt,v 1.2 2004/12/06 08:58:45 zuihu Exp $ RCSのテスト
ci.mac を実行後
$Id: remoteclog.txt,v 1.2 2004/12/06 08:58:45 zuihu Exp $ RCSのテスト
ファイルを編集
$Id: remoteclog.txt,v 1.2 2004/12/06 08:58:45 zuihu Exp $ RCSのテスト テスト続行
もう一度 ci.mac を実行
$Id: remoteclog.txt,v 1.2 2004/12/06 08:58:45 zuihu Exp $ RCSのテスト テスト続行
rlog.mac を実行すると編集履歴が表示される。
RCS file: RCS/citest.txt,v Working file: citest.txt head: 1.2 branch: locks: access list: symbolic names: keyword substitution: kv total revisions: 2; selected revisions: 2 description: test ---------------------------- revision 1.2 date: 2004/12/03 02:47:46; author: zuihu; state: Exp; lines: +2 -1 rev2 ---------------------------- revision 1.1 date: 2004/12/03 02:47:17; author: zuihu; state: Exp; init ============================================
v1.1 と v1.2 の違いを表示するには、rcsdiff.mac を実行する。
====================================================== RCS file: RCS/citest.txt,v retrieving revision 1.1 retrieving revision 1.2 diff -r1.1 -r1.2 1c1 < $Id: remoteclog.txt,v 1.2 2004/12/06 08:58:45 zuihu Exp $ --- > $Id: remoteclog.txt,v 1.2 2004/12/06 08:58:45 zuihu Exp $ 2a3 > テスト続行
ここまでくれば、あなたも立派なリビジョニストになったといえよう。
(2004-12-03 02:17:26)



 というのは大型の美しい蝶である。この蝶は、何百キロも海を渡ることが知られている。
というのは大型の美しい蝶である。この蝶は、何百キロも海を渡ることが知られている。
